Anthropic dropped a new batch of Claude Managed Agents features last week: dreaming, outcomes, multiagent orchestration, and webhooks. The coverage was mostly what you’d expect. Feature descriptions. A quote from an enterprise customer. Some pricing math.
I read it differently.
I run a 7-agent Claude pipeline that publishes this blog every day. When Anthropic announced the infrastructure layer that handles “months of work before you ship anything users see,” I wasn’t reading as a potential customer evaluating something new. I was reading as someone who already built the thing they’re selling, and trying to figure out which parts of my code I should delete.
That’s a different take than the tech press is running. So here it is.
What Managed Agents Is (The 30-Second Version)
Quick orientation if you haven’t been following this: Anthropic launched Claude Managed Agents on April 8, 2026, as a hosted infrastructure product for running long-horizon agents.
The pitch: instead of building your own agent loop, sandboxed execution environment, session persistence, crash recovery, and tool execution layer, you give Anthropic a system prompt and a tool configuration, and they run the harness. You get the output.
Three concepts to understand:
- Agent: your model choice, system prompt, tools, and MCP servers
- Environment: a cloud container with whatever packages your agent needs
- Session: a running instance of your agent doing a specific task
Pricing is standard Claude API token costs plus $0.08 per session-hour of active runtime. That $0.08 is the rent on Anthropic’s infrastructure. You’re not building the apartment; you’re renting it.
On May 6, 2026, Anthropic added four things on top of that foundation: dreaming (research preview), outcomes (public beta), multiagent orchestration (public beta), and webhooks.
Now let’s actually look at them.
The Pipeline I’m Comparing Against
Before I can tell you what these features mean, you need to know what I’m comparing them against. The context matters. 🔧
I’ve written about this before (how I use Claude Code to run this blog and the blast-radius guardrails I run), but here’s the short version.
Seven agents, each with a specific job:
- Editorial Planner (orchestrator)
- Content Researcher
- Content Writer
- Fact Checker
- SEO Strategist
- Image Creator
- WordPress Publisher
The Editorial Planner runs at 8am ET daily via cron. It checks the calendar, pulls the next topic, and delegates each step to the appropriate specialist. No agent starts until the one before it has signed off. Fact Checker must approve before SEO touches the draft. SEO must approve before Image Creator runs. Publisher runs last. If you want to see exactly how each of those seven agents is wired up, I wrote out my exact subagents workflow.
All writes go through git. The WordPress Publisher uses a separate WP user account whose underlying role restricts what it can do (and the code adds an additional layer with no DELETE HTTP path defined). And every run starts with a lockfile to prevent two instances from stepping on each other:
# One instance at a time. If the lock exists, the new run exits clean.
flock -n /tmp/pipeline.lock bash -c 'python3 scripts/run-pipeline.py'This runs on a DigitalOcean VPS that’s separate from the Hostinger box where WordPress lives. (If you’re curious why that split exists, I broke down my actual stack and the reasoning behind it.) The pipeline never has credentials for the production database. It talks to WordPress only through the REST API with the scoped app password.
That’s what I’m comparing Managed Agents against.
Dreaming: The One Feature I Don’t Have an Equivalent For
Let me start with the most interesting one.
Dreaming is a scheduled process that reviews your agent’s past sessions and memory stores, extracts patterns from what worked and what didn’t, and updates the agent’s memory so it gets better over time. Anthropic describes it as agents that “self-improve” between runs. It’s in research preview right now and requires a form request to access.
Harvey, the legal AI company, reported roughly a 6x improvement in agent completion rates in their internal tests after enabling dreaming. That’s a number worth paying attention to even if your use case isn’t legal drafting.
Here’s my honest take: this is the only feature on the list where I have NO hand-rolled equivalent.
Every morning when my pipeline runs, it starts with the same CLAUDE.md, the same agent prompts, the same tool configurations. If the Fact Checker made a mistake two weeks ago and I corrected it manually, that correction doesn’t propagate back into the agent’s memory. The agent doesn’t know it happened. The same mistake is one bad run away from recurring.
Dreaming solves that. It’s a feedback loop I don’t have.
For my use case (daily blog publishing), this is a modest improvement. The pipeline already has a multi-pass review loop that catches most errors before they publish. But for agents doing longer-horizon work, customer support, or anything where “remembered preference” matters, dreaming is genuinely new infrastructure that would take significant effort to replicate manually.
If I were starting a new agent project from scratch, dreaming would be near the top of my “reasons to use Managed Agents” list.
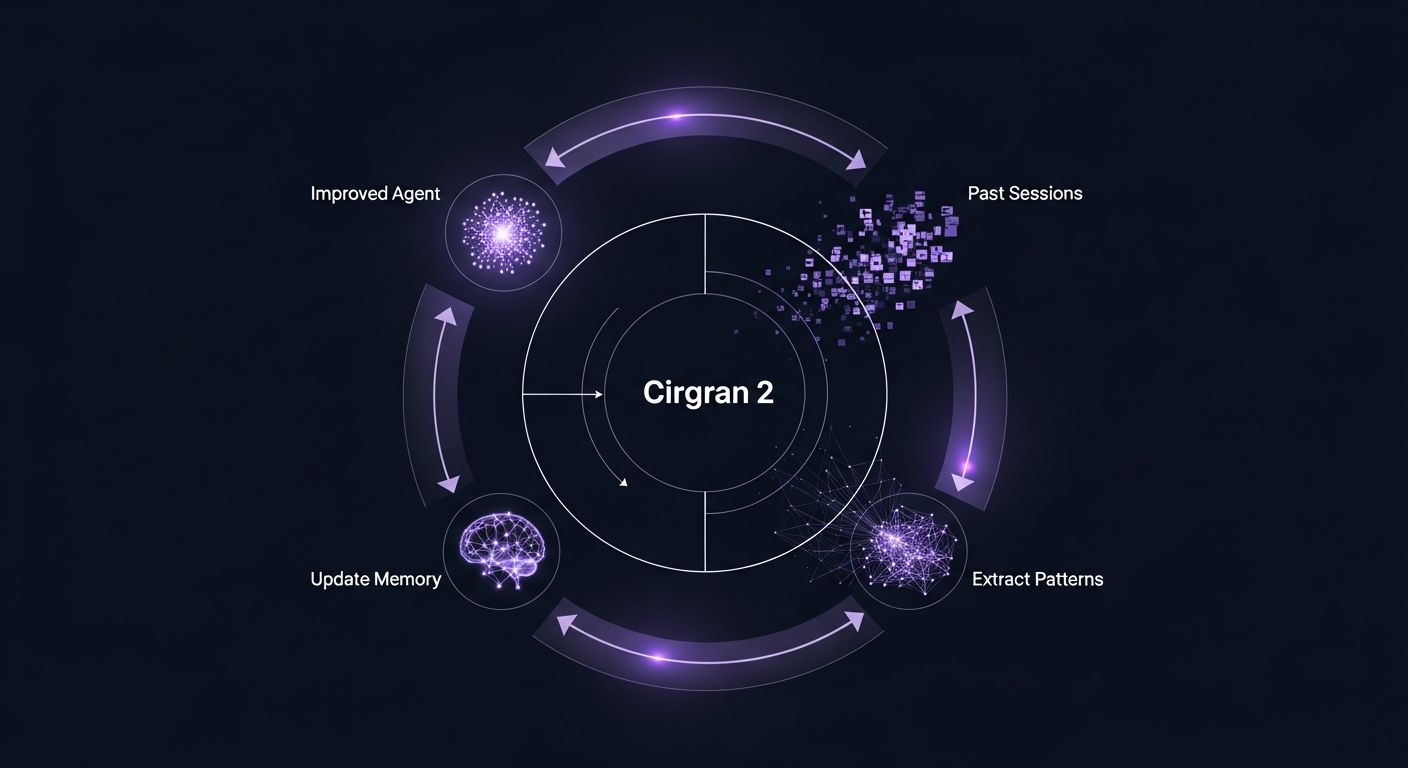
Outcomes: I Built This Manually and It Took Weeks
Outcomes lets you write a success rubric in plain text. The system uses a separate grader (not the same model that produced the output) to evaluate whether the agent’s work meets that rubric. If it doesn’t, the grader tells the agent specifically what fell short, and the agent takes another pass.
Anthropic measured a 10-percentage-point improvement in task success over standard prompting, with file generation specifically showing +8.4% for Word documents and +10.1% for PowerPoint files.
I have a version of this already. It’s just ugly.
My multi-pass review loop in CLAUDE.md is basically a manually orchestrated rubric system. Each agent in the sign-off chain has a specific job: Fact Checker verifies claims, SEO Strategist checks keywords and meta, Image Creator confirms visuals (and yes, some of those visuals are built by Claude in code rather than generated as images). If any of them flag a problem, the Writer revises and the whole chain re-runs from that point.
The critical difference is the grader separation. My agents use the same Claude instance to do the original work AND the review. That means there’s potential for the same biases to affect both passes. The Managed Agents outcomes feature uses a separate grader explicitly to prevent that bias.
That’s a genuine architectural improvement over what I built.
For my current pipeline, swapping in native Outcomes would mean throwing away a few hundred lines of orchestrator logic in exchange for something more reliable. The migration cost is real. But if you’re building a new pipeline from scratch, you’d be silly to reinvent Outcomes manually.
Multiagent Orchestration: Same Pattern, Different Wiring
Multiagent orchestration in Managed Agents means a lead agent that breaks work into pieces and delegates to specialists, each with their own model, prompt, and tools. The specialists can run in parallel on a shared filesystem and contribute their outputs back to the lead agent.
I already have this. My Editorial Planner is the lead agent. The six specialists are the workers. So my reaction here isn’t “interesting new feature.” It’s “yes, that’s the design pattern, what does Anthropic’s version do differently?”
A few things worth noting:
The parallel execution is the key difference. My pipeline runs sequentially. Writer goes first. Then Fact Checker. Then SEO. That’s by design, because each step depends on the previous one being complete. But there are legitimate use cases where parallel execution is the right call: research tasks where multiple subtopics can be investigated simultaneously, for example, or data analysis where you’re pulling from multiple independent sources.
For my blog pipeline, parallel execution would actually break things. Fact Checker running simultaneously with the Writer doesn’t make sense. Sequential is right here.
But for a project where the tasks are genuinely parallelizable? Native orchestration in Managed Agents saves you from building the routing logic yourself. The full execution trace is visible in the Claude Console, which is a debugging tool I’d genuinely use.
Then Opus 4.8 shipped on May 28, 2026, and the orchestration picture changed in one specific way.
Dynamic Workflows is a new capability in Managed Agents where a single Opus model acts as a lead coordinator and dispatches work to hundreds of parallel subagents simultaneously, with dynamic task assignment and result aggregation. This is meaningfully different from the multiagent orchestration feature that launched on May 6. That earlier feature was lead-agent-plus-specialists. Dynamic Workflows is lead-agent-plus-fleet.
I need to update what I said before: the reason I’m not switching isn’t that Anthropic’s parallel execution story is weak. My pipeline runs sequentially by design: Fact Checker has to see the Writer’s draft before SEO can run, and that ordering is intentional. The block on migration is pipeline architecture, not capability gap.
For a different workload, this matters. If you’re writing a pipeline that needs to scan 500 URLs in parallel and synthesize results, or run a research agent that pulls from 50 independent sources simultaneously, Dynamic Workflows is a real step up from anything you’d build by hand. The sequential-by-design blog pipeline just isn’t that use case.
So: Anthropic closed a gap. I want to say that clearly because the previous version of this post implied they hadn’t.
Webhooks: Useful, But Not for What I’m Doing
Webhooks let you define an outcome and receive a POST notification when the agent finishes. It’s the async handoff: you fire the session, go do something else, and get pinged when it’s done.
My pipeline doesn’t need this.
Cron schedules work differently from webhooks. Cron is time-driven: “run at 8am every day.” Webhooks are event-driven: “run when X happens, and notify me when you’re done.” My pipeline has no trigger except the clock.
Where webhooks would change things for me is a use case I haven’t built yet: something reactive. A reader submits a feedback form, an agent processes it, a webhook fires when the processing is complete. Or inbound support tickets for Trigli, my AI customer support SaaS: a ticket arrives, the agent handles it, a webhook tells the CRM to update the ticket status.
For event-driven agent architectures, webhooks are table stakes. For scheduled pipelines, they’re not relevant.
If you’re building reactive agents: use them. If you’re building scheduled pipelines: probably not the feature you care about.
What Opus 4.8 Changes for This Calculus
Beyond Dynamic Workflows, Opus 4.8 added two other things worth mentioning for anyone evaluating Managed Agents for a scheduled pipeline.
Effort Controls: The Feature I Actually Want
Opus 4.8 introduced per-step compute modes: default, extra, and max. Each mode unlocks higher rate limits and signals to the model how much work you want it to do.
For a multi-step pipeline with uneven workloads, this is useful in a way the session-hour pricing structure never was. The Researcher needs deep reasoning. The Publisher mostly needs reliable execution. Right now I handle that by choosing different models per step. With effort controls, you could run the same model at different effort levels per step, scaling compute where it matters and pulling back where it doesn’t.
My hand-rolled version doesn’t have an equivalent. I can pick models. I can’t dial the reasoning depth on a per-call basis without switching models entirely. That’s a narrow but real capability gap.
Agent Guardrails
Managed Agents also lets you define guardrails in the agent configuration itself: policy definitions in YAML or natural language that scope what the agent can and can’t do during a session. The platform enforces these at runtime.
If you’ve read the blast-radius post, you know I handle this at the architecture level: scoped WP user, no DELETE path, lockfiles. The Managed Agents version does some of that at the platform level rather than in your code. They’re complementary, not one replacing the other. If I were migrating, I’d keep my code-level restrictions AND use the agent-definition scoping for defense in depth.
So Would I Actually Switch to Managed Agents?
Here’s where I’ll be direct about the lock-in math.
The honest answer for my current setup: no, and not because Managed Agents is bad.
My pipeline is already running. It handles hundreds of publishing decisions a month. The hard infrastructure problems are solved: crash recovery (the flock lockfile and cron retry behavior handle most failure modes), session persistence (git is my audit trail), scoped permissions (separate WP user, no DELETE path). What I’d gain from switching is crash recovery that’s more sophisticated than mine, native dreaming, and a grader I don’t have to build.
What I’d give up: I’d be handing the harness to Anthropic. That means their timeline when they deprecate a feature or change pricing. It means per-session costs that scale with my run frequency. And it means the pipeline lives on their infrastructure rather than on a server I control.
For a hand-rolled pipeline that’s working, the migration cost is real and the benefits are marginal. The tool already fits the hand.
For a new project? Different answer. If I were starting Trigli’s agentic support pipeline from scratch today, I’d take a hard look at Managed Agents. The $0.08/session-hour is cheap relative to the developer time it would save. The dreaming feature alone would give me a feedback loop I’d otherwise have to build. And Outcomes would replace a state machine I’d otherwise spend weeks writing.
The lock-in question is real, though. Anthropic controls the harness. That’s a genuine trade-off, not a small-print footnote. If that matters for your use case (compliance, on-prem requirements, budget predictability at scale), the Claude Agent SDK or a fully hand-rolled solution is the right call.
If it doesn’t matter, and you just want to ship something that works without building infrastructure for six months first, Managed Agents is the honest answer.
My Take on Each Feature, Ranked by “Would I Use This”
For people skimming: here’s where I land.
Dreaming: would genuinely improve my pipeline. No hand-rolled equivalent. Would adopt if starting fresh or if the research preview opens up and the improvement holds at production scale.
Outcomes: the concept is solid and the separate grader is a real architectural improvement over my version. High migration cost to swap into an existing pipeline. Build it in from day one on new projects.
Multiagent Orchestration: already have the pattern. Managed Agents version adds parallel execution and native console visibility. Useful for new projects; not a compelling migration reason for existing ones.
Dynamic Workflows (Opus 4.8): now I’d consider it for the right workload. For sequential pipelines, the design choice (not a capability gap) is still the blocker. For parallel research and data synthesis, this is a legitimate upgrade over anything hand-rolled.
Effort controls: the feature I’d actually use if migrating. Per-step compute budgeting with corresponding rate limit expansion is genuinely different from model-switching and something I can’t replicate in the hand-rolled stack today.
Webhooks: not relevant for my scheduled pipeline. Essential for event-driven architectures. Know which one you’re building before deciding how much you care about this.
Sources
- New in Claude Managed Agents: dreaming, outcomes, and multiagent orchestration (Official Anthropic blog post, May 6, 2026)
- Claude Managed Agents overview documentation (Official Anthropic documentation)
- Claude Managed Agents launch post (Official Anthropic blog post, April 8, 2026)
- Scaling Managed Agents: Decoupling the brain from the hands (Official Anthropic engineering post)
- Claude Managed Agents vs Agent SDK comparison (WaveSpeed.ai analysis)
- Anthropic updates Claude Managed Agents with three new features (9to5Mac, May 7, 2026)
- Anthropic introduces dreaming (VentureBeat)
- Claude Opus 4.8: Dynamic Workflows, effort controls, and Agent Guardrails (Anthropic, May 28, 2026)
What Do You Think?
If you’re running your own agent pipeline, I’d genuinely like to know where you land on this. The lock-in question is one I’m still thinking through myself.
Are you evaluating Managed Agents? Already using it? Building something on the Agent SDK instead? Drop a comment below or reach out on X. I read everything.
And if you want the full picture on how my pipeline handles permissions and blast radius, the AI agent blast radius post has more detail than you probably want. 😄 And while you’re thinking about how Claude behaves in long sessions, I wrote about the verbal tics and work-deferral patterns Claude Code users have been documenting on Reddit. And if you’re still at the foundational tool-choice stage, I wrote about why I chose Claude over ChatGPT and why I still haven’t gone back.